
Подробная пошаговая инструкция по сборке семантических ядер для аналитики, сайта, контекстной рекламы. Способы очистки, кластеризации, для формирования публикаций, распределения запросов по разделам веб-проекта
Семантическое ядро — фундаментальная составляющая для:
- аналитики,
- сайта,
- публикаций,
- контекстной рекламы.
Общий процесс сборки СЯ
В общем виде сборку запросов можно представить так:
- придумать направления,
- дособрать направления,
- собрать запросы,
- очистить запросы.
Разберем данный процесс на примере, предположив что мы занимаемся доставкой воды.
Придумываем направления
Направления не должны пересекаться между собой. Т.е. если мы выбираем запрос:
вода
то добирать направление:
заказать воду
уже не имеет смысла, т.к. "заказать воду" уже будет включен в кластер "вода".
Для нашей цели, из головы на вскидку придумываем следующие направления:
вода доставка,
вода заказать.
Сразу стоит отметить, что данные направления не полны. В рамках данной статьи процесс сборки упрощен с целью показа основных принципов и подходов при формировании СЯ. В действительно боевом проекте может получиться 50, 100 и даже 500 направлений.
Дособираем направления
Для того чтобы максимально подробно собрать необходимые нам запросы, идём на вордстат, вводим:
доставка вода
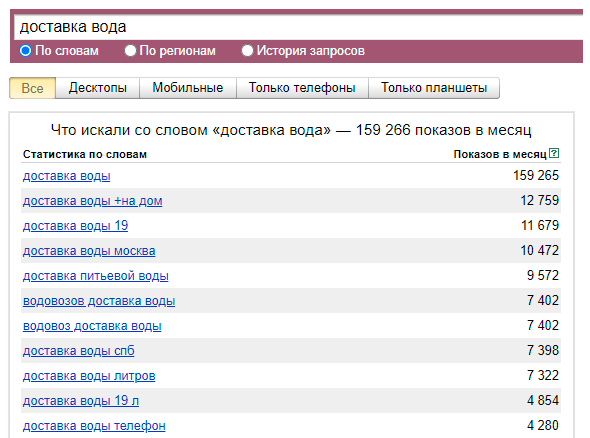
и смотрим в столбце "Запросы, похожие на "доставка вода" " (данный столбец называется некоторыми специалистами "ЭХО") какие еще направления могут быть полезны:

Кроме всего прочего проверяем другие направления и запросы которые потенциально могли бы нам подойти:
Так же можно вводить в поиске запросы, после чего пролистывать вниз страницы, где можно увидеть смежные направления:
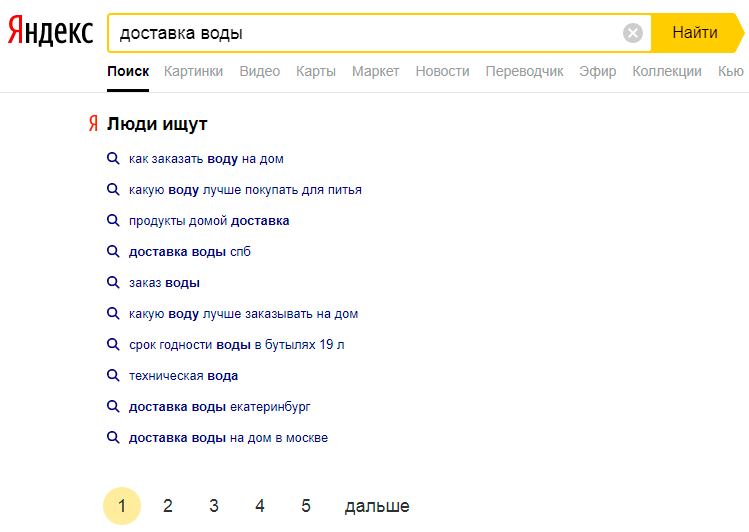
После изучения статистики и мозгового штурма получаем подобный список:
вода доставка,
вода заказать,
вода офис,
вода питьевая.
История с google несколько иная, здесь нельзя просто взять ввести направления и получить запросы, т.к. сервиса подобного яндекс вордстат у гугл нет. Однако можно взять уже собранные запросы из вордстат и с помощью планировщика запросов google проверить их.
Парсим/собираем запросы
Чтобы ускорить данный процесс можно использовать плагины-парсеры запросов яндекс вордстат, например:
- Yandex Wordstat парсер запросов,
- яндекс wordstat assistant.
Можно воспользоваться платной SEOшной программой keycollector, либо её бесплатным аналогом "словоёб".
Самый банальный подход — это копирование в ручном режиме всех запросов с каждой страницы выдачи по каждому из выбранных направлений. Следует копировать руками все запросы в таблицу, что является самым бесперспективным способом, т.к. через неделю подобной работы желание собирать запросы в ручном режиме отпадёт гарантированно.
Воспользуемся keycollector'ом и для нашего примера создадим 4 папки, для каждого выбранного направления:
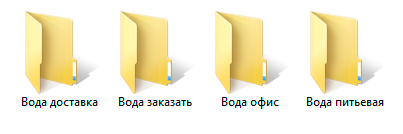
Это нужно для того чтобы структурированно хранить исходники, запросы и группы. Соберем данные из вордстат в соответствии с нашей геозависимостью (мы соберем для Санкт-Петербурга). Экспортируем проекты в csv формате, после чего пересохраняем в xlsx, удалив ненужные, пустые столбцы. После подобных манипуляций в каждой папке будет примерно следующее содержимое:

Содержимое документа "Вода доставка.xlsx":
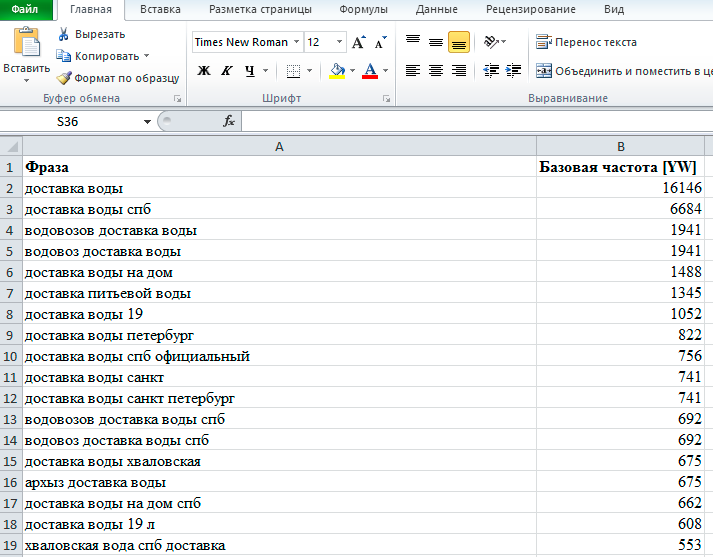
Очищаем запросы
Пожалуй самый трудоемкий процесс, который занимает максимум времени — очистка запросов. В зависимости от задач, поставленных перед специалистом, способы очистки могут отличаться, так например можно собирать семантическое ядро для решения различных задач:
- Настройка рекламы
- Распределение запросов по сайту
- Аналитика и прогнозирование
- Написание публикаций.
Для того чтобы сэкономить время, следует просмотреть списки запросов и в зависимости от целей и задач собрать список стоп слов (по др. минус-слова).
Стоп слова/минус-слова
Стоп слова (по др. минус-слова, минус-фразы) - это запросы, которые встречаются часто в большом количестве, при этом являются мусорными, пустыми, неподходящими, ненужными. Списки стоп-слов важно собирать для того, чтобы быстро и просто отсеивать ненужные запросы. Кроме всего прочего, обычно ядер несколько, а вот список минус-слов для каждого ядра один.
Для нашего примера, неподходящими запросами автоматически становятся те, которые содержат региональность отличную от СПБ.
Соответственно, один из списоков стоп слов будет содержать весь список городов и регионов России, за исключением Санкт-Петербурга, Ленинградской области, СПБ, Лен обл и пр. Т.е. следует оставить те запросы, которые нам потенциально полезны. В сети можно найти базы городов и регионов России с помощью которых заминусить ядро.
Запросы для аналитики
Для расчета потенциального трафика, уже достаточно высочостотных запросов и их частотностей в месяц.
Если же нужны какие-то особенные данные, по типу расчета KEI (коэффициента эффективности запросов), следует собирать уточняющие данные для каждого запроса на основе яндекс.директ, поисковой выдачи, либо средствами. Для минималистичной и простейшей формулой предлагаемой самим keycollector'ом:
( YandexWordstatBaseFreq / 2) * ( YandexWordstatBaseFreq / 2) / KEI_YandexDocCount
Где:
YandexWordstatBaseFreq - это базовая частота запросов (уже есть)
KEI_YandexDocCount - это количество документов в поисковой выдаче (собирается отдельно)
Запросы и данные для аналитики собираются для задач по типу: оценить, посчитать, спрогнозировать, а следовательно и вариаций для расчетов может быть крайне много.
Очистка СЯ для сайта
Для сайта оставляются исключительно информационные, собственные брендовые (если есть), а так же коммерческие запросы.
Возможна сборка уточняющих частотностей, т.е. запросы такого вида:
"доставка воды"
"!доставка !воды"
а так же дополнительной информации. Как правило, на данном этапе удаляются неявные дубли, т.е. располагая запросами такого вида:
заказать доставку воды
заказать доставку воды п
но заказать доставку воды
После удаления неявных дублей, останется только такой запрос:
заказать доставку воды
Стоп-слова для сайта
Для сайта абсолютно не нужны запросы:
- чужие брендовые,
- с ненормативной лексикой
- с неподходящим геопозиционированием,
- несезонные.
Выборка запросов для СЯ контекстной рекламы
Для контекстной рекламы существует 2 основных подхода:
- точная подборка,
- общая подборка.
Точная подборка муторна и производится в случаях, когда планируется тонко настроить запросы для контекстной рекламы, уменьшая количество отказов, сокращая затрачиваемые бюджеты. Данный вид выборки запросов может выглядеть так:
Заказать доставку воды +минеральной
как правило, подобные запросы для СЯ рекламы формируются на основе 4 и более сложных фраз.
Общая подборка — это подборка целевых, теплых, брендовых, околотематических (если позволяет бюджет) запросов.
Стоп-слова для контекстной рекламы
В списке стоп слов для контекстной рекламы, чаще всего присуствуют информационные запросы. Такое формирование списка стоп слов для рекламы, как правило связано с экономией бюджета, при наличии обширного семантического ядра.
СЯ для публикаций
Семантическое ядро для публикаций должно содержать исключительно коммерческие и информационные запросы.
Логично и верно брать коммерческие запросы для распределения их по разделам сайта:
цена доставка вода
стоимость доставка вода
заказать доставка вода
Важно брать информационные запросы:
как организовать доставку воды
как открыть доставку воды
И не брать:
Доставка вода капель
Доставка вода спутник
Доставка вода Волгоград
В итоге
Семантическое ядро может собираться для различных задач, это могут быть запросы для сайта, контекстной рекламы, данные по аналитике. Важно внимательно относиться к данному процессу, так как важно иметь возможность вернуться к каждому этапу, чтобы его перепрофилировать под новые задачи.